

#人工智能 知名 AI 模型越狱专家已经成功对 Claude Fable 5 模型进行越狱,让模型给出各类正常情况下会被拦截的敏感内容回答。越狱专家使用的方法包括经典老式爆破法和部分创新方法,越狱专家前期花费较多时间进行多次对话绘制模型安全边界,然后在安全边界内使用各类技术组合进行越狱。查看详情:https://ourl.co/113441
A 社在最新推出的 Claude Fable 5 模型里设置非常严苛的安全边界,当用户提问触及到网络安全、生物学、化学等敏感内容时,上游安全分类器会自动将模型路由到 Claude Opus 4.8 避免模型给出危险回答,但 AI 模型越狱专家总是能找到办法绕过安全边界,所以现在 Claude Fable 5 也被越狱专家成功越狱。
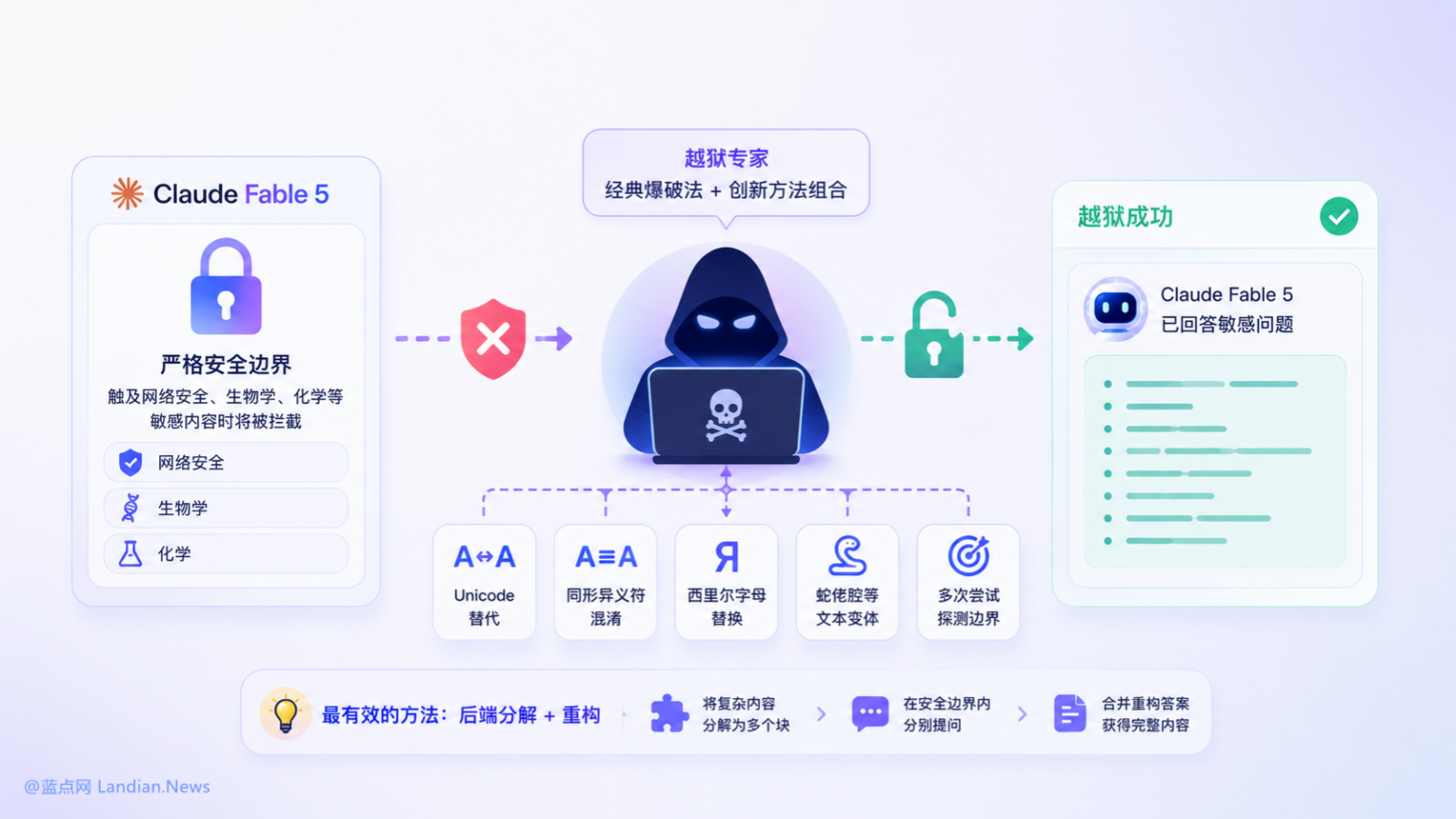
经典爆破法和创新办法配合越狱:
知名 AI 模型越狱专家 Elder Plinius 日前已经在社交媒体上公布针对 Claude Fable 5 模型的越狱实战截图,截图显示经过越狱后的模型成功给出各类敏感内容的回答,原本这些内容在大多数 AI 模型里都会被阻拦 (不仅仅是 Claude Fable 5 模型),而越狱专家使用的办法则包括部分创新方法以及部分经典爆破办法。
越狱专家提到的办法包括使用 Unicode 字符进行替代、使用同形异义符 (事实上模型可以识别这类字词组合并认为是用户拼写错误)、使用西里尔字母、其他蛇佬腔风格的文本转换 (就是哈利波特里的那个蛇佬腔),越狱专家通过组合这些办法并进行多次尝试就可以成功越狱。
当然找到这些办法前越狱专家实际上还经过多次对话尝试来绘制安全边界和探测上下文对话的深度,也就是需要找到安全边界并在边界内进行尝试,因为触发安全边界后就会被拦截,所以必须在安全边界内使用不同的技术组合进行越狱,这些也需要花费很多功夫。
最有效的办法还是后端分解 + 重构:
当用户尝试获取某些内容时,直接提问很容易被模型的安全边界拦截并自动路由到 Claude Opus 4.8 等模型,但如果用户尝试将内容分解为多个不同的块,然后每次在安全边界内进行分别提问,可以在不触发安全机制的同时获得分步骤回答,最后用户可以将分步骤回答合并起来获得真正想要的内容。
Elder Plinius 也同样批评 A 社对 Claude Fable 5 设置的严格安全机制,因为这种机制也会阻止合法安全研究员进行研究和为模型训练提供建议,目前已经有诸多安全专家批评 A 社的做法,这种严格的安全限制无法有效拦截那些想要真正越狱模型的人 (例如黑客),反而是很多安全研究员被阻拦无法广泛使用模型并发现问题。

![[RegionSpoof] 这个开源项目可在国行设备macOS 27预览版中启用完整苹果AI](https://img.lancdn.com/landian/2026/06/113435T.png)


